Roosevelt's Recession: A Historical and Econometric Examination of the Roots of the 1937 Recession
Searching for a Cause: An Econometric Analysis
Of the factors hypothesized to have caused the Recession, the goal of this chapter is to examine, quantitatively, the predictive power of each hypothesized variable on an indicator of overall economic wellbeing. What complicates an analysis of the 1937 Recession is the specificity of the hypothesized casual factors. For example, the wage hypothesis centers not on increased wages in general, but instead on the NLRA-induced wage increase. As another example, Friedman’s money supply argument hinges not on the decrease in money supply, but instead on the decrease in money supply as caused by the reserve requirement increases. The prolonged and unresolved debate about the Recession, coupled with the very narrow scope of each hypothesized factor, necessitates the formation of finely tailored variables. In this chapter, variable choices are explained in detail to provide the reader a clear understanding of the choices made and to allow the reader to gauge the applicability of the variables to the arguments they are intended to capture.
Before embarking any further on a quantitative analysis, it is important to draw a distinction between intent and methodological outcomes. As is usually the case with time series regression analysis of historical time periods, modeling is made more difficult by the lack of accurate data and the infrequency of historical data recording. If data availability is of concern in a regression analysis, practitioners often decide to expand the number of observations. In other words, the focal time period is expanded or examined at smaller sub-intervals. This decision serves as a preventative measure against model irrelevancy. The number of observations is of high importance in statistical testing. Generally, the larger the number of observations, the greater the likelihood that a model can accurately deduce minute relationships. Unfortunately, given the time period of interest, the issue of observation count is more pronounced.
This analysis seeks to gauge the magnitude of impact that each proposed cause of the Recession had on bringing about the downturn. However, on a relatively short ten-year timeline, the Recession is flanked on both ends by historical events that had unprecedented effects on both society and the economy. Both the Great Depression (early 1930s) and World War II (early 1940s) impacted the economy on a scale larger than that of the Recession. Given that the focus is only the 1937 Recession, this analysis must be confined to the months between January 1935 and December 1938.176 The imposed time constraint allows a model to more accurately calculate the comparatively smaller magnitude of only recession-related developments.Although it poses drawbacks, the short time interval used provides an uncommon benefit. Because economic indicators fluctuated widely and unexpectedly during the four-year time span examined, autocorrelation poses less of an issue. Simply put, autocorrelation exists when a variable is a function of its former self. In the context of severe autocorrelation, the significance of model results must be closely scrutinized.
Data
Regressands
Advertisement
A comprehensive measure that captures the 1937 downturn must be used as the dependent variable across all models in order to examine the causal role played by the different hypothesized factors. Traditionally, studies of the Recession use either industrial production or gross domestic product as the regressand. Later in this chapter, both measures are gauged for their applicability and usefulness.
The industrial production variable was obtained from the Federal Reserve.177 The Federal Reserve’s monthly dataset, indexed to January 1935, measures the real output of all manufacturing, mining, and electric and gas utility facilities located in the United States. The variable is plotted in Figure 9.
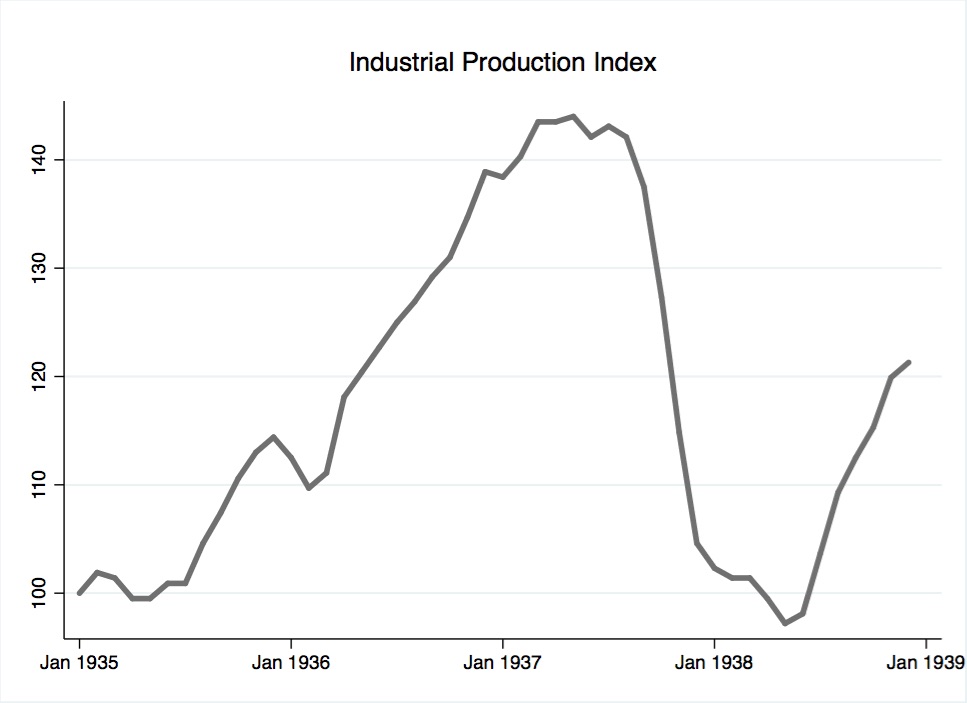{kind=link}
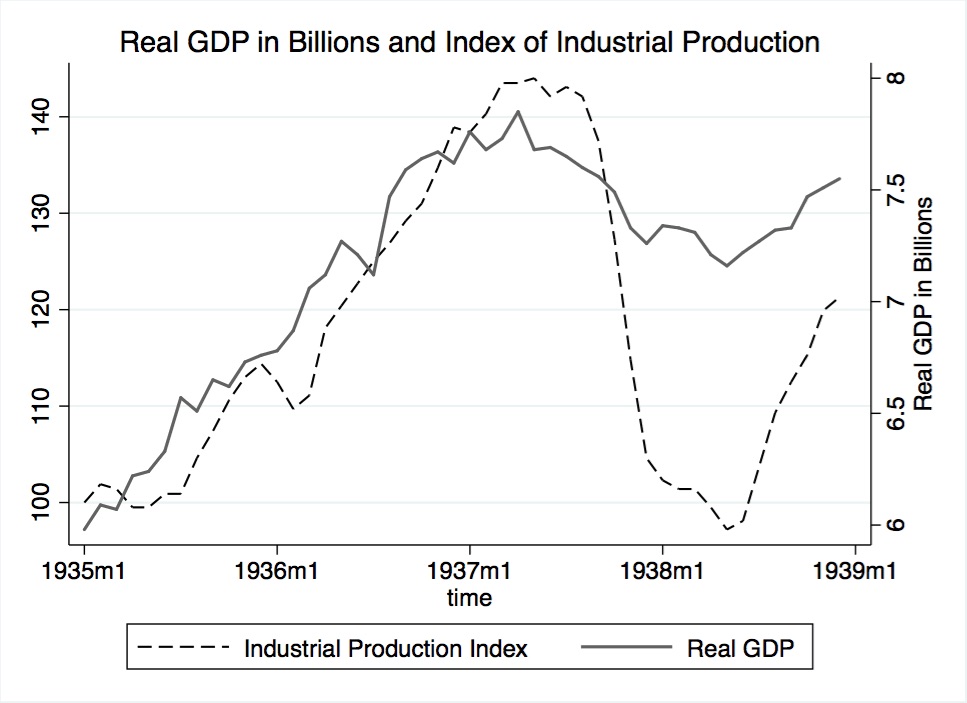
The search for the alternative regressand, GDP, was more elusive. During the focal time period, GDP had not yet been adopted as a measure of aggregate output. Furthermore, historic measures of output used during the time period are incompatible for use in this study because they are provided only on an annual basis. Luckily, other papers concerned with this time period have addressed the issue of monthly data availability. This study utilizes as the alternative regressand a monthly real GDP variable obtained from the Gordon-Krenn monthly and quarterly dataset for 1913-1954.178 Figure 10 plots the real GDP variable.
Gordon and Krenn’s dataset provides reliable and important data that is unavailable from traditional sources, like the NBER. Facing the same issue of data availability, Gordon and Krenn converted annual GDP component data to quarterly and monthly intervals, using the Chow-Lin interpolation. For each annual GDP component, Gordon and Krenn used monthly NBER datasets, chosen for their high correlation with the annual GDP component of interest, to ensure an accurate conversion process. Finally, they summed the new monthly component data to provide a measure of monthly GDP.179
Although both industrial production and GDP show a clear decline during the Recession, each variable varies significantly in the percent change realized. For comparative purposes, Figure 10 combines industrial production, as shown in Figure 9, and real GDP. During the Recession, the decline in industrial production was greater than that of GDP because the Recession impacted industry most severely. Given the difference in percent change, both indicators are used in order to examine the downturn in a more nuanced manner.
{kind=link}
Figure 10. Industrial production index and real GDP in billions, 1935-1938. Source: Refer to footnotes 177 and 178.
Fiscal Policy
The fiscal policy variable used in this study, real government expenditures in 1937 dollars, was obtained from the Gordon and Krenn dataset and is plotted Figure 11. They transformed NBER series 15005, federal budget expenditures, into real terms. Subsequently, they removed the value of transfer payments, like the Soldier’s Bonus, that were included in the original NBER series. They removed transfer payments because their government-spending variable was to be used in calculating monthly GDP.180 Gordon and Krenn’s dataset is used because it requires no further adjustment. However, there may be need for a dummy variable to account for the large dip in spending that occurred during the first two months of bonus disbursement.
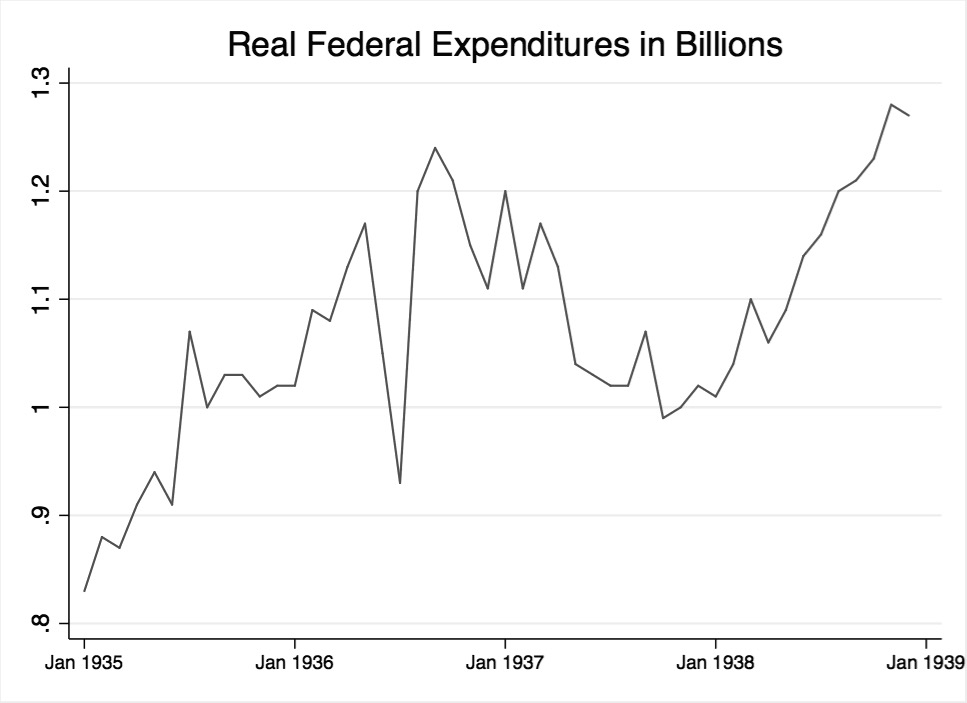{kind=link}
Wages
The wage increase caused by the NLRA was historically hypothesized to have contributed to the Recession. Although recent research discounts this view, it is nonetheless important to examine the casual impact, if any, of the NLRA. The search for a wage variable required the fulfillment of two prerequisites:
- The variable must be confined to industries impacted by the NLRA.
- The variable’s NLRA-induced fluctuations shouldn't be overshadowed by wage fluctuations unrelated to the NLRA.
At first glance, the first requirement may seem overly restrictive given the Recession’s national impact. However, it’s important to remember that the manufacturing industry, arguably the most important and largest industry at the time, was directly impacted by NLRA regulations. With this point in mind, the variable search was confined to the manufacturing sector in the interest of excluding wage effects from large but non-regulated industries. Fulfillment of the second requirement is crucial to this study because a wage variable is included to test only the impact of the NLRA-induced wage increases on the economy. A wage variable that fluctuates with non-NLRA factors the interpretation of the NLRA’s impact more difficult.
The variable search started with NBER macrohistory database series 08283, production worker wage cost per unit of output. However, this variable’s denominator, manufacturing output, declined during the Recession to a greater degree than its numerator: wages. The variable is incompatible for use because the NLRA-induced wage increase is not the only factor causing major fluctuations in value.
The variable ultimately chosen for use in modeling was wages per hour worked in manufacturing, a slight variation of the aforementioned series, wages per unit output in manufacturing. The new variable was created by dividing the index of real factory payrolls (NBER macrohistory series 08242) by the index of production worker manhours in manufacturing (NBER macrohistory series 08265).181 Wages per manhours worked, henceforth referred to as the wage variable, was chosen because the variable minimizes fluctuations caused by the Recession, while it maximizes fluctuations caused by the NLRA. The wage variable highlights the impact of the NLRA because it is less reflective of broader changes in the economy. By construction, it provides a clearer understanding of labor costs because wages are considered per unit output realized.
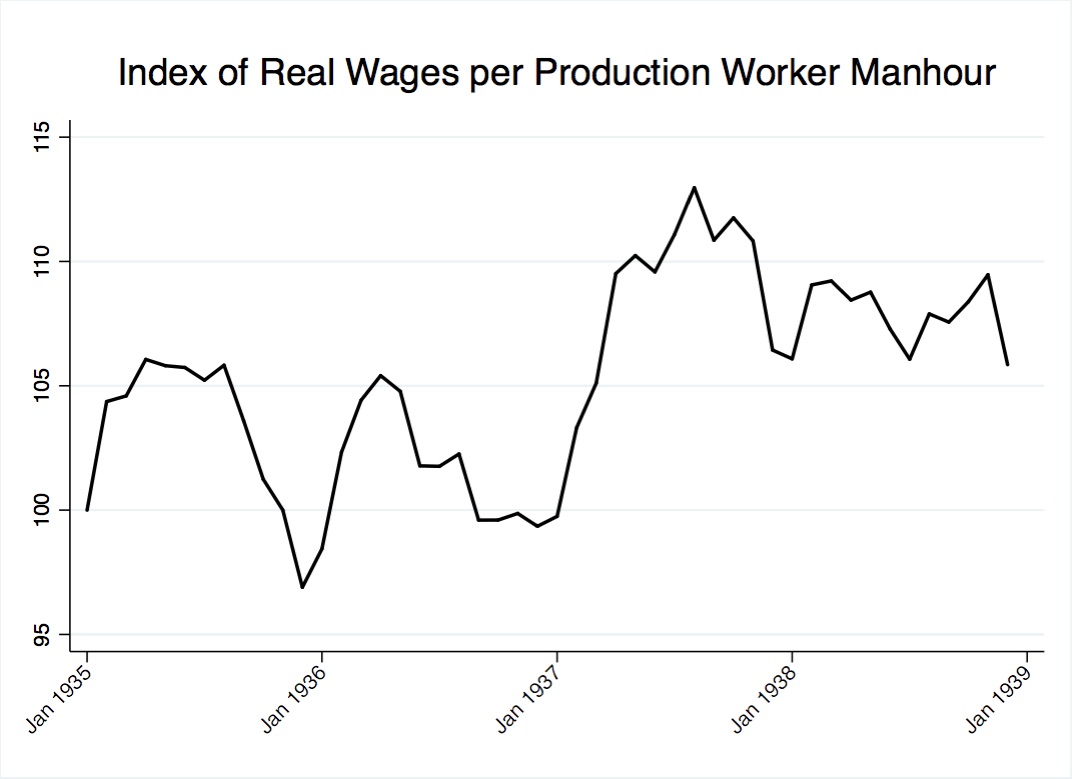
Figure 12 and Figure 13 visualize the desirability of the chosen wage variable. As shown in Figure 12, industrial production, real wages, and manhours worked exhibit a near 1:1 relationship. On the other hand, Figure 13, a plot of wages per manhour worked, shows more nuanced fluctuations. It’s important to note that during the NLRA-impact period, from 1936 to late-1937, the wage variable realizes a 10% increase. The size of the increase is comparable to the increase in manufacturing sector wages reported by Cole and Ohanian and plotted in the previous chapter, Figure 7. The post-1937 plot of the wage variable is also comparable to the post-1937 plateau of manufacturing sector wages in Figure 7.
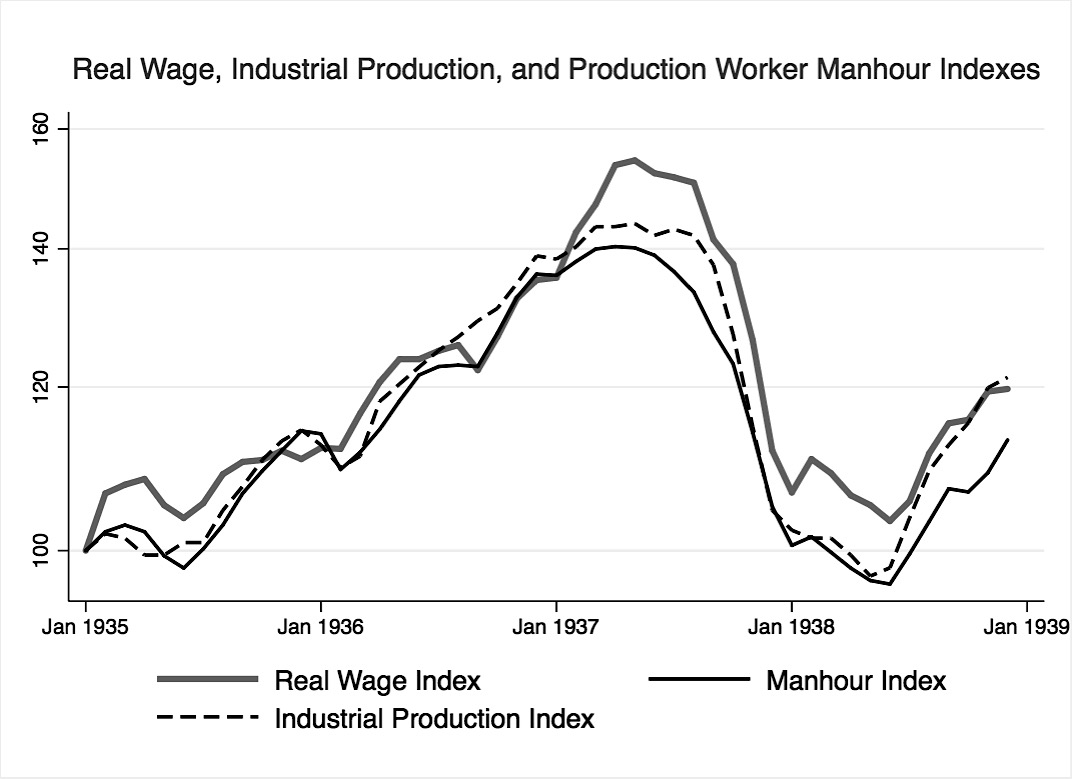{kind=link}
Figure 12. Index of real wages, industrial production, and production worker manhours. Data adapted from: NBER macrohistory database series 08242 and 08265.
{kind=link}
Figure 13. Wage variable used in study, index of real wages per production worker manhours.
Data adapted from: NBER macrohistory database series 08242 and 08265.
Money Supply
It is necessary to examine the banking sectors’ response to the increased reserve requirements prior to choosing a variable that reflects the impact of monetary policy on the money supply.182 However, the NBER macrohistory database does not provide distinct datasets for excess and required reserves held. As a workaround, two NBER datasets were used to calculate distinct measures for excess and required reserves.183 To split the NBER’s total reserves dataset into its excess and required component parts, the equations below were solved for each monthly observation point:
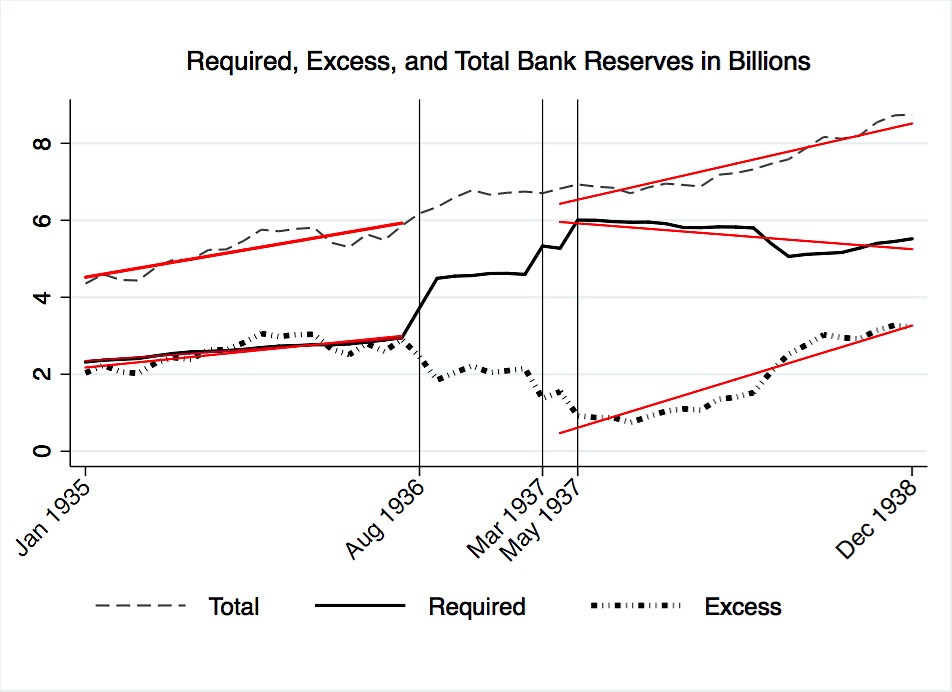
Total reserves, required reserves, and excess reserves are plotted in Figure 14. Vertical lines mark the Federal Reserve’s three reserve requirement increases. For each line plot, a line of best fit is superimposed for the months preceding the Federal Reserve’s first increase in August 1936. Similarly, a line of best fit is added to each plot onwards from April 1937; April is situated one month after the second reserve requirement increase and one month before the third.
Figure 14 shows that banks responded to the reserve requirement increases by further padding their reserves. After the first increase, excess reserves declined as banks shifted funds to required holdings. However, after the third increase, banks started to accumulate excess reserves. Given that total required reserves remained relatively stable after the third increase, and given that total excess reserves increased during the same time, it can be assumed that banks accumulated excess reserves by liquidating assets that would have otherwise been put to alternative use. Clearly, the risk-averse banking sector desired a cushion of excess reserves.
{kind=link}
In his paper on the 1937 recession, Velde also concluded that excess reserve accumulation was reactionary. Instead of examining aggregated national data like that used in Figure 14, Velde studied the behavior of banks by member class. He found that central reserve city banks, like those in New York and Chicago, in 1937 were “considerably closer to their [reserve] limit than banks in reserve cities and country banks.”184 Central reserve city banks faced significantly greater excess reserve depletion than other member banks. This class of member banks was at the forefront of excess reserve accumulation.185 Therefore, the post-April 1937 positive slope of Figure 14’s excess reserves plot was most greatly influenced by central reserve city bank accumulation.
Although the Federal Reserve succeeded in making excess reserves unusable, banks responded by hoarding as excess even more assets. During the focal time period, the banking sector treated excess reserves not as a pool of money to be utilized, but as a lifeline locked away for use in times of crises. Having confirmed the banking sector’s excess reserve accumulation as reactionary accumulation, the measure of money supply to be used in this study will exclude both required and excess reserves from its sum.
It is the unfortunate reality that some contemporary studies of the Recession utilize standardized measures of the money supply, like M1 or M2, to characterize their variables without explicitly defining the component parts of the measure used. Because contemporary measures of money supply did not exist in the 1930s, it is sometimes difficult to neatly classify long-defunct institutions, like the postal savings bank, under measures crafted for a modern banking system. Adding to the confusion when examining historic studies, the standardized measures in use today were the product of a 1980s redefinition of the existing “M”s. To avoid any confusion, the money supply variable used in this study will not be classified as any current standard measure.
NBER macrohistory database series 14144a, money stock in billions of dollars, is used in the creation of the money supply variable. Series 14144a is the seasonally adjusted sum of currency held by the public, all commercial bank demand deposits, and all commercial bank time deposits. Prior to creating a money supply variable, total reserves held (series 14064) and money stock (series 14144a) were deflated using Gordon and Krenn’s GDP deflator.186
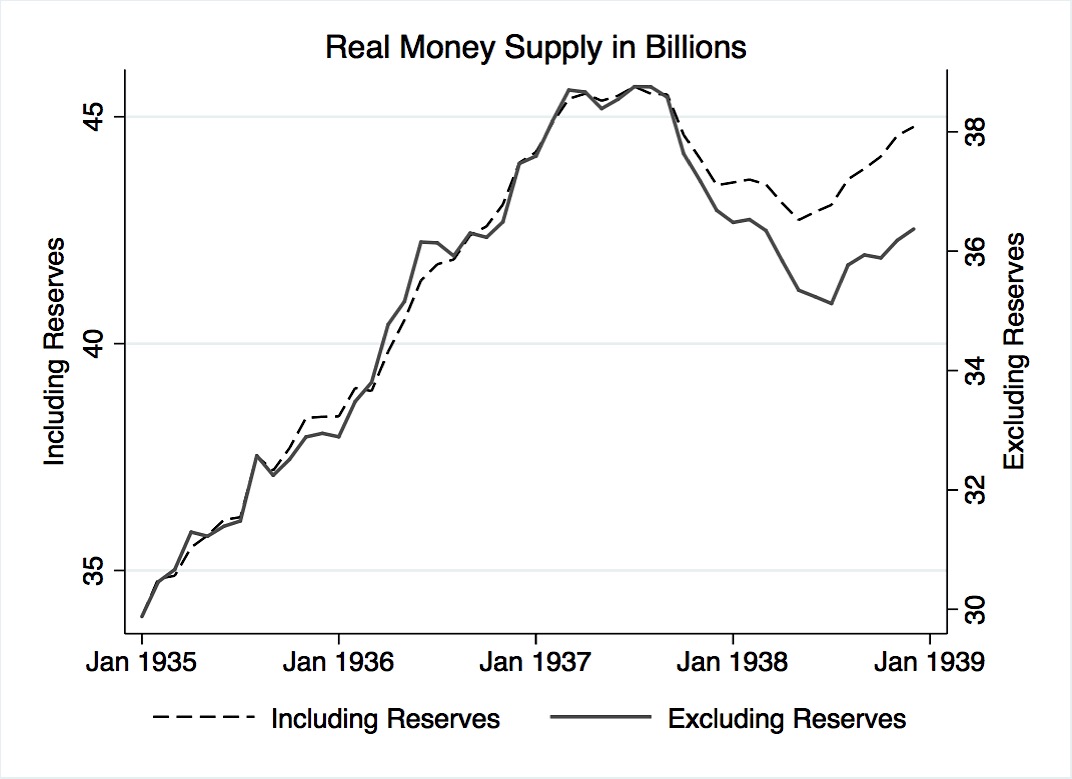
Figure 15 plots two possible renditions of money supply. The dashed line plots real money supply, the deflated series 14144a. By construction, the series includes in its sum total reserves held. The solid line plots real money supply excluding real total reserves.187 As is clear in the post-1937 plot period, the increase in total reserves, caused mainly by an accumulation of new excess reserves, had a negative impact on the already decreasing money supply. Whereas prior to 1937, both line plots in the figure have a near 1:1 relationship, in the months after 1937, money supply exclusive of total reserves decreased to a greater extent than money supply inclusive of reserves. Therefore, the variable used in subsequent modeling is money supply excluding reserves, henceforth referred to only as money supply.188
{kind=link}
Figure 15. Real money supply including and excluding total reserves. Data adapted from: NBER macrohistory database series 14064 and 14144a.
Federal Budget Receipts
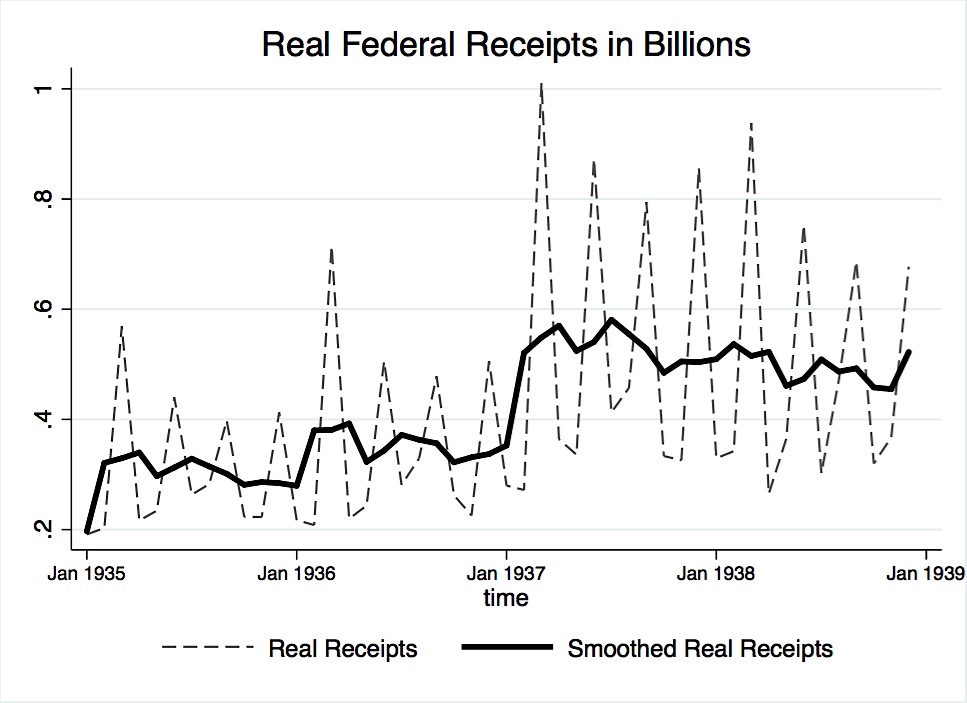
Although not of much interest, a tax variable is used in modeling. NBER series 15004, total federal budget receipts in millions, was chosen for use. The NBER’s dataset was transformed into billions of dollars and deflated using the Gordon and Krenn deflator. Because it was not seasonally adjusted by the NBER, the variable was smoothed using a moving average of the previous, present, and future month. Figure 16 plots real federal budget receipts before and after smoothing.
{kind=link}
Examining the Variables
The variables are log-transformed in order to normalize the data. A log-log model allows for a simple interpretation of the coefficients: a 1% increase in an independent variable leads to a percent change of the regressand that is equivalent to the value of the coefficient output. To gain a better understanding of the variables under consideration, and to aid in model specification, focus was paid to identifying the time-series properties of each variable.
To test for serial correlation of the logged real GDP variable, a correlogram was performed. The correlogram provides two important measures, the autocorrelation and partial autocorrelation functions. The autocorrelation function measures the variable’s correlation with itself at each lag. The partial autocorrelation function, at each lag, is a regression of the variable and that lag, holding all others lags constant. Figure A-1 plots GDP’s autocorrelation function. The plot shows that GDP is significantly correlated with up to three previous years. The plot shows a prolonged and somewhat smooth decay of the autocorrelation function, hinting that the data may be non-stationary. Given the decay of the autocorrelation function, GDP is an autoregressive process.
The partial autocorrelation function of GDP is plotted in Figure A-2. The plot provides a more precise visualization of the autoregressive process. As shown in the figure, when the effect of the first lag is controlled for, the correlation of all other lags is, generally, insignificant. Although the function shows significant correlations at lags 1, 6, 13, 16, and 21, it should be underscored that the function cuts off and remains insignificant for five lags after the first. Given the non-zero partial autocorrelation of the first lag, coupled with the long lag delay before other significant spikes arise, it is assumed that GDP is an AR(1) process. The assumption of an AR(1) process is underscored by Figure A-3, a scatterplot of GDP and its first lag, and Figure A-4, a scatterplot of GDP and its second lag. Both plots have clear upward trends that are usually associated with an autoregressive processes.
Given the very high correlation between the income variable and its lags, coupled with the previous tests that indicate an autoregressive process, the analysis continues by examining the type of autoregressive process seen in GDP. To test for a unit root, a Dickey-Fuller test was performed. The null hypothesis is that the variable contains a unit root. The test was performed and produced an output of -2.841, with the p-value being 0.0526. The low p-value barely misses the 95% significance level, indicating that the null hypothesis cannot be rejected. The test was also performed using an increasing number of lags (5-11). The additional tests confirmed that the null hypothesis couldn’t be rejected. Having confirmed the existence of a unit root, the variable is now said to be a random walk. Further Dickey-Fuller tests were used to specify the type of random walk.
The variable can either be a random walk with drift or without drift. A random walk without drift is a process where the current value of a variable is composed of its past values plus an error term. A random walk with drift is, essentially, a random walk with an added constant parameter. GDP was tested for drift and test’s p-value was 0.0034. The null hypothesis can be rejected, and the results held with the use of varying lag lengths. GDP is a random walk without drift. GDP, a variable confirmed to be a random walk without drift, was also tested for a deterministic time trend. The test statistic output was -1.642 with a p-value of .7754. GDP is a unit root around a deterministic time trend. A regression of GDP and time further confirmed the existence of a time trend. Because the GDP variable is non-stationary, it is used in modeling in its differenced form.
The tests performed above were repeated on the industrial production variable. Figure A-5, the autocorrelation function of industrial production, shows a steep but smooth decay. Figure A-6, the partial autocorrelation function, is significant at lags 1, 2, with some peaks after lag 10. These graphs suggest that industrial production is an autoregressive. Next, a Dickey Fuller test for unit root was performed. With and without varying lags included, the test output indicated a unit root. The test was repeated with trend added. At varying lags, the test output confirmed the existence of a unit root with a deterministic time trend. However, the test for drift produced inconclusive results. Therefore, the assumption is made that industrial production is a unit root with a deterministic time trend. Like the GDP variable, industrial production will be differenced when used as a regressand. Given that both possible dependent variables are used in differenced form, independent variables will also be differenced to make the interpretation of model results simpler.
Building a Model
To consider whether industrial production or GDP should be used as the dependent variable, each regressor was individually regressed by up to 4 differenced lags on the two possible regressands. After each regression, a Durbin-Watson test and Breusch-Godfrey test was performed to look for autocorrelation between the regressor variable and the regressand under consideration. The simple regression results are reported in Table A-4 and the Breusch-Godfrey test outputs are reported in Table A-5. Overwhelmingly, when each independent variable was individually regressed on industrial production, the Durbin-Watson test and the Breusch-Godfrey test indicated autocorrelation of the error terms. Therefore, GDP was chosen as the dependent variable to be used in modeling.
The first model used included 3 differenced lags of each independent variable. The results of Model 1 are reported in Table A-1, alongside results for models soon to be discussed. Due to the use of lagged variables in Model 1, the Breusch-Godfrey (BG) test was the prime test of interest. Unlike the Durbin-Watson test, the BG test allows for lagged dependent variables and tests for higher order autoregressive processes. The test output is reported in Table A-2. Based on the reported p-values, the null hypothesis that serial correlation does not exist, was not rejected. In other words, the assumption was made that serial correlation does not exist.
Before further analyzing results, Model 1 residuals were tested for problems. Figure A-7 plots residuals against fitted values. The graph shows a random scatter, a preliminary indicator that the results were favorable. Furthermore, Figure A-8 shows that the residuals are somewhat normally distributed. It should be noted that Figure A-9, a scatterplot of the residuals against time, appears to be random with no patterns. The autocorrelation function, Figure A-10, shows no lags of significance, and the partial autocorrelation function, Figure A-11, shows no lags of significance. A runs test indicated that the residuals had 24 runs. The p-value output provided was 0.72; the null hypothesis is that the residuals were produced from a random process, which was not rejected. This test further indicated that autocorrelation was not a problem in the model. Finally, Dickey Fuller tests without drift, with drift, and with trend were performed on the residuals. All three tests had p-value outputs of 0.00, thereby raising no concerns regarding a unit root of the residuals. Based on testing of the residuals, the standard error outputs provided in Model 1 were not biased.
To continue improving the model, the wage variable was incorporated in Model 1.1 in its unlogged form. The output of Model 1.1 is reported in Table A-1. The fit of the model improved slightly and the regression results remained comparable to Model 1. Given this slight improvement, coupled with the favorable BG test results reported in Table A-2, the wage variable was retained for use in its unlogged form.
Due to their removal of the Soldier’s Bonus impact, the Gordon and Krenn data for government spending declines sharply in June 1936 and July 1936. In Model 2, a time dummy variable for these two months was included to remove a potential source of bias. The inclusion of the dummy variable removed a slight bias from regression results; however, the dummy variable was insignificant in all models.
Model 3 builds upon Model 2 by using a different measure of the money supply variable. In line with other studies of the Recession, the money supply variable in Model 3 was changed to include total reserves. The results of this regression, with all other variables kept unchanged from Model 2, are reported in Table A-3. Although the fiscal policy coefficient does not change as a result of the variable change, the coefficient of money supply increased from .42 in Model 2 to .61 in Model 3. These results should be considered surprising because the variable, having strayed from the argument that reserve hoarding decreased money supply, has now a greater impact in the regression. The money supply coefficients in Model 3 are counterintuitive and the results suggest that other studies, utilizing measures inclusive of reserves, may have inadvertently inflated the role of money supply. Given that the government-spending coefficient remained unchanged in Model 3 and given the reasons for excluding reserves, the next model retained money supply exclusive of reserves.
The final model examined, Model 4, was a cleaned regression of only the significant variable-level lags.189 Reported in Table A-3, the fit of this regression remained high while the variable coefficients and beta coefficients continued to mirror those previously modeled. Furthermore, this model’s BG test, as reported in Table A-2, produced an output even more favorable than that of the other models. Model 4’s residual plots, Figure A- 12 to Figure A- 15, were all favorable.Continued on Next Page »